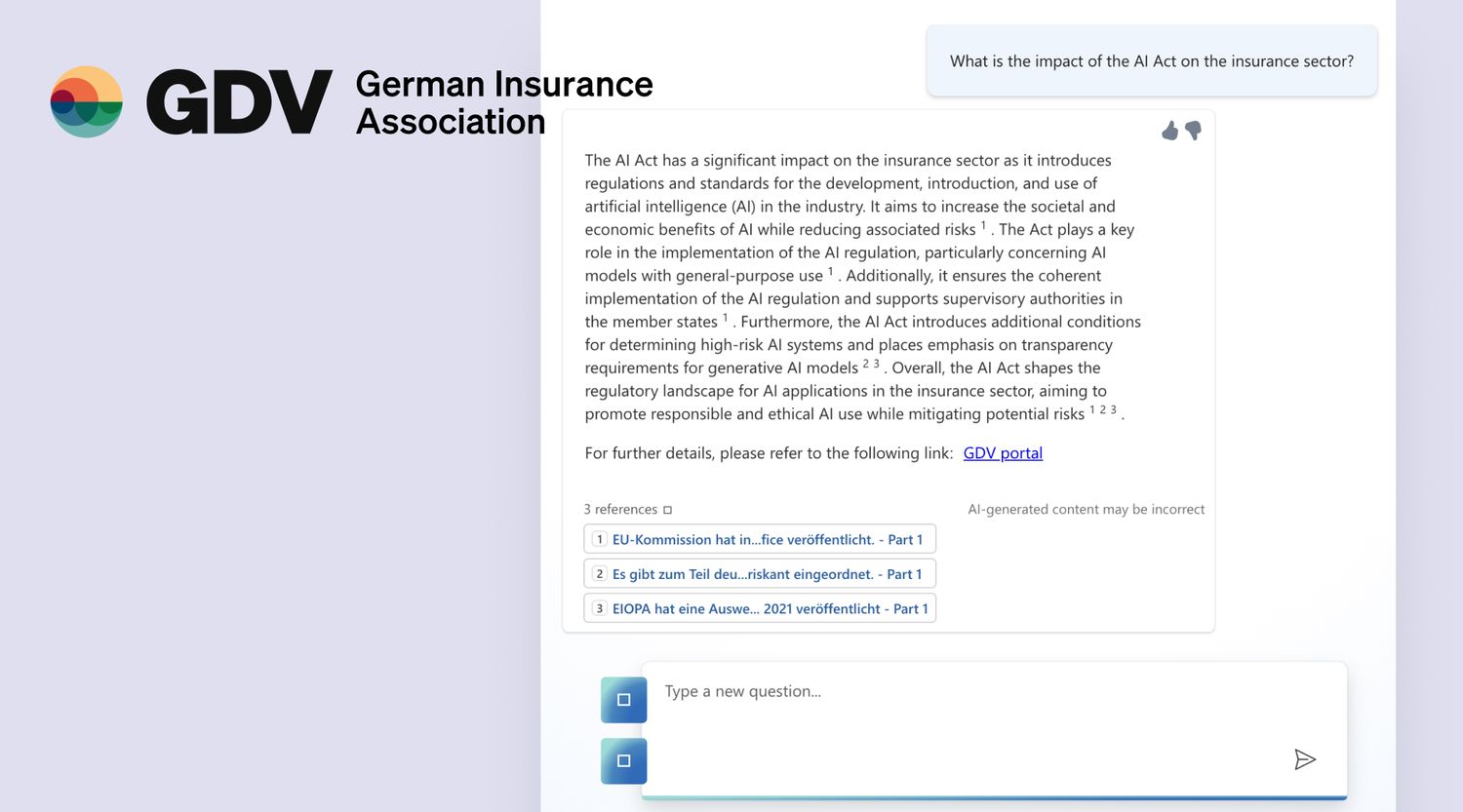
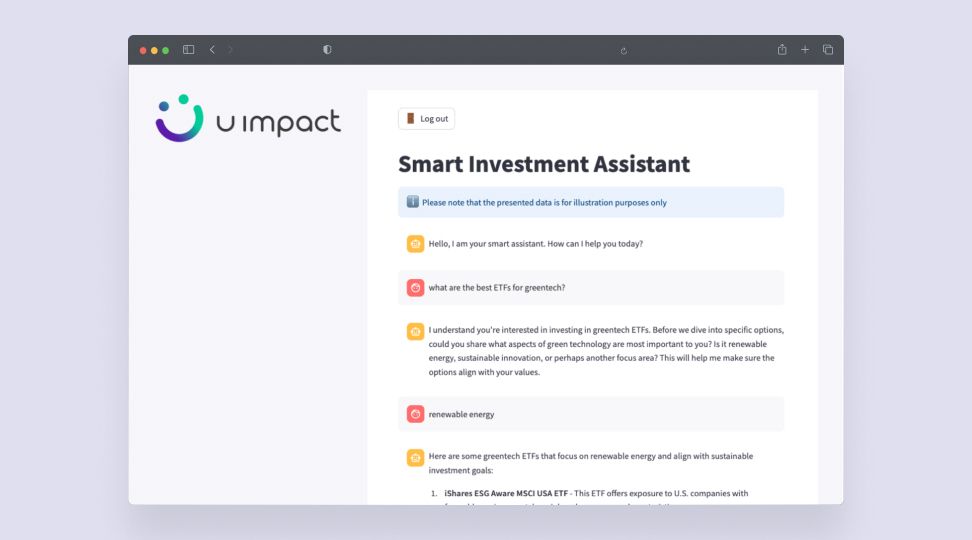
Instant Answers
- Get definitive answers from your data in seconds
- Responses include reference links to source documents
- Multilingual by default for global accessibility

EU Compliant
- EU hosted and aligned with the EU AI Act
- Data protection compliant with GDPR regulations
- Secure access controls and audit trails

Data Integration
- Integrate internal data sources from your organization
- Include public data sources